
Abstract
Brain-computer interfaces (BCIs) promise to enable vital functions, such as speech and prosthetic control, for individuals with neuromotor impairments. Central to their success are neural decoders, models that map neural activity to intended behavior. Current learning-based decoding approaches fall into two classes: simple, causal models that lack generalization, or complex, non-causal models that generalize and scale offline but struggle in real-time settings. Both face a common challenge, their reliance on power-hungry artificial neural network backbones, which makes integration into real-world, resource-limited systems difficult. Spiking neural networks (SNNs) offer a promising alternative. Because they operate causally (i.e. only on present and past inputs) these models are suitable for real-time use, and their low energy demands make them ideal for battery-constrained environments. To this end, we introduce Spikachu: a scalable, causal, and energy-efficient neural decoding framework based on SNNs. Our approach processes binned spikes directly by projecting them into a shared latent space, where spiking modules, adapted to the timing of the input, extract relevant features; these latent representations are then integrated and decoded to generate behavioral predictions. We evaluate our approach on 113 recording sessions from 6 non-human primates, totaling 43 hours of recordings. Our method outperforms causal baselines when trained on single sessions using between 2.26× and 418.81× less energy. Furthermore, we demonstrate that scaling up training to multiple sessions and subjects improves performance and enables few-shot transfer to unseen sessions, subjects, and tasks. Overall, Spikachu introduces a scalable, online-compatible neural decoding framework based on SNNs, whose performance is competitive relative to state-of-the-art models while consuming orders of magnitude less energy.
Mission
Design constraints of neural decoders
Deep learning has transformed neural decoding, moving beyond traditional methods that depend on hand-crafted features. Artificial neural networks (ANNs) can now learn to map neural activity to intended actions directly from data, unlocking far greater performance. Yet, building neural decoders that are practical for real-world brain-computer interface (BCI) systems remains an open challenge. To be truly effective, models must balance multiple constraints:
- Energy efficiency: Neural decoders need to be energy-efficient to operate within the tight power budgets of battery-constrained implantable BCI devices.
- Causality: To enable online operation, models must be causal (i.e. rely only on present and past inputs).
- Scalability: Models need to scale to heterogeneous neural datasets, since scaling has been shown to boost decoding performance in multiple domains including neural decoding.
- Generalization: Models should generalize to new subjects and tasks with minimal training examples to reduce the need for lengthy calibration sessions that hinder the practical deployment of BCIs.

Figure 1: Constraints of practical neural decoding models.
The landscape of neural decoders
While significant progress has been made along each of these constraints, to our knowledge, no single framework excels across all of them simultaneously. Existing approaches tend to fall into two main categories, each with its own shortcomings.
| Model | Energy efficiency | Causality | Scalability | Generalization |
|---|---|---|---|---|
| "Simple": Wiener Filter, MLPs, GRUs, ... | ➖ | ✚ | ➖ | ➖ |
| "Sophisticated": Cebra, LFADS, POYO, MICrONS, ... | ➖ | ➖ | ✚ | ✚ |
Table 1: The landscape of neural decoders.
On one hand, simple models, often based on traditional architectures like multi-layer perceptrons (MLPs) or Gated Recurrent Units (GRUs), tend to perform well within individual experiments. These methods are typically causal, making them particularly attractive for online applications, but require homogeneous input structures, making them difficult to scale or generalize across subjects. On the other hand, more sophisticated frameworks that can be trained across datasets have demonstrated strong performance and generalization, particularly at scale. However, their lack of causal processing and heavy computational demands challenges their applicability outside the research lab.
An unexplored alternative for neural decoding
Spiking neural networks offer a promising alternative. Their inherent causality supports integration into online systems, and their low computational footprint makes them well-suited for battery-constrained environments such as implantable BCIs.

Figure 2: Schematic comparison between artificial neural networks vs spiking neural networks.
Unlike conventional ANNs which rely on static activations like ReLU, which are always active during inference, SNNs employ stateful activations like the Leaky-Integrate-and-Fire, which only activate when they spike. This property makes SNNs remarkably energy-efficient during inference compared to ANNs, particularly when deployed on neuromorphic hardware. Furthermore, their event-driven, online nature makes them well-suited for processing real-time or asynchronous data streams like spike trains.
Approach
In this work, we asked a simple but fundamental question: Can we build effective neural decoders using spiking neural networks? To answer this question, we introduce Spikachu: a causal, scalable, and energy-efficient framework for neural decoding based on spiking neural networks. Our framework consists of two main components, outlined below.
ANN Harmonizer
- Tokenization: We extend the formulation of binned spikes by binning neural activity and representing each spike as a token using learnable embeddings, similar to Azabou et al. (2023).
- Harmonizer: The tokenized neural activity of a timebine is then projected into a common latent space, shared across sessions and subjects using the PerceiverIO encoder.

Figure 3: Overview of the Spikachu framework.
SNN Backbone
After harmonizing the data, we process the latents with a series of SNN modules which are far more energy-efficient than ANNs:
- Multi scale SNN I: This module processes the latent through parallel spiking MLPs, each operating at different temporal scales.
- Spiking self attention: This module processes the latent for long-range dependencies across temporal scales using the attention variant introduced by Zhou et al. (2023).
- Spiking MLP: This module mixes the spatial and temporal information of the latents and projects them to a low-dimensional representation.
- Multi scale SNN II: This module again uses parallel spiking MLPs to process the latents at different temporal scales.
- Membrane potential observer layer: This layer is composed of neurons that never spike and whose membrane potential never resets. Instead of monitoring their output, we use their membrane potential to track continuous variables.
- Linear: This conventional linear layer projects the membrane potential of the observer neurons to behavioral predictions.
Evaluation
Dataset
To evaluate Spikachu's effectiveness for causal, scalable, and energy efficient neural decoding we worked with a large collection of publically available datasets curated by Azabou et al. (2023) and Pei et al. (2021) that can be accessed through Dandi (used in this work) or brainsets. The dataset contains electrophysiological recordings from motor cortical regions of monkeys performing motor tasks of varying complexities.
- Center Out (CO): a relatively stereotyped task where the animal controls a cursor that begins at the center of a screen. After a go cue, the animal reaches toward one of eight targets and then returns to center.
- Random Target (RT): a more complex task where the monkey makes self-paced movements, with new targets appearing in succession at random screen locations.
- Touchscreen Random Target (RTT): a continuous variant of the random target task which was performed on a touchscreen tablet instead of using a manipulandum.
- Maze: for this task, the animal performs reaches from an initial location while carefully avoiding the boundaries of a virtual maze, using a touchscreen tablet instead of a manipulandum.

Figure 4: Datasets used in this work. Lock represents animals that were held-out for testing.
In total, this dataset spans over 100 behavioral sessions, 43 hours of recordings, with 10,410 units from the primary motor (M1) and premotor (PMd) regions in the cortex of 6 nonhuman primates, and more than 20 million behavioral samples providing a rich foundation to thoroughly assess our approach.
| Study | Regions | Tasks | # Individuals | # Sessions | # Units | # Spikes | # Behavior Timepoints |
|---|---|---|---|---|---|---|---|
| Perich et al. | M1, PMd | Center Out, Random Target | 4 | 111 | 10,410 | 111.39M | 20M |
| NLB-Maze | M1 | Maze | 1 | 1 | 182 | 3.6M | 6.8M |
| NLB-RTT | M1, S1 | Random Target | 1 | 1 | 130 | 1.5M | 2.8M |
Table 2: Datasets used in this work.
Benchmarking on single-sessions
We first benchmarked our approach on a single-session setting. To do so, we trained single-session models on 99 recording sessions from Perich et al. (2018). Along Spikachu, we trained a variety of traditional and state-of-the-art models used for neural decoding to benchmark spikachu's pertformance.
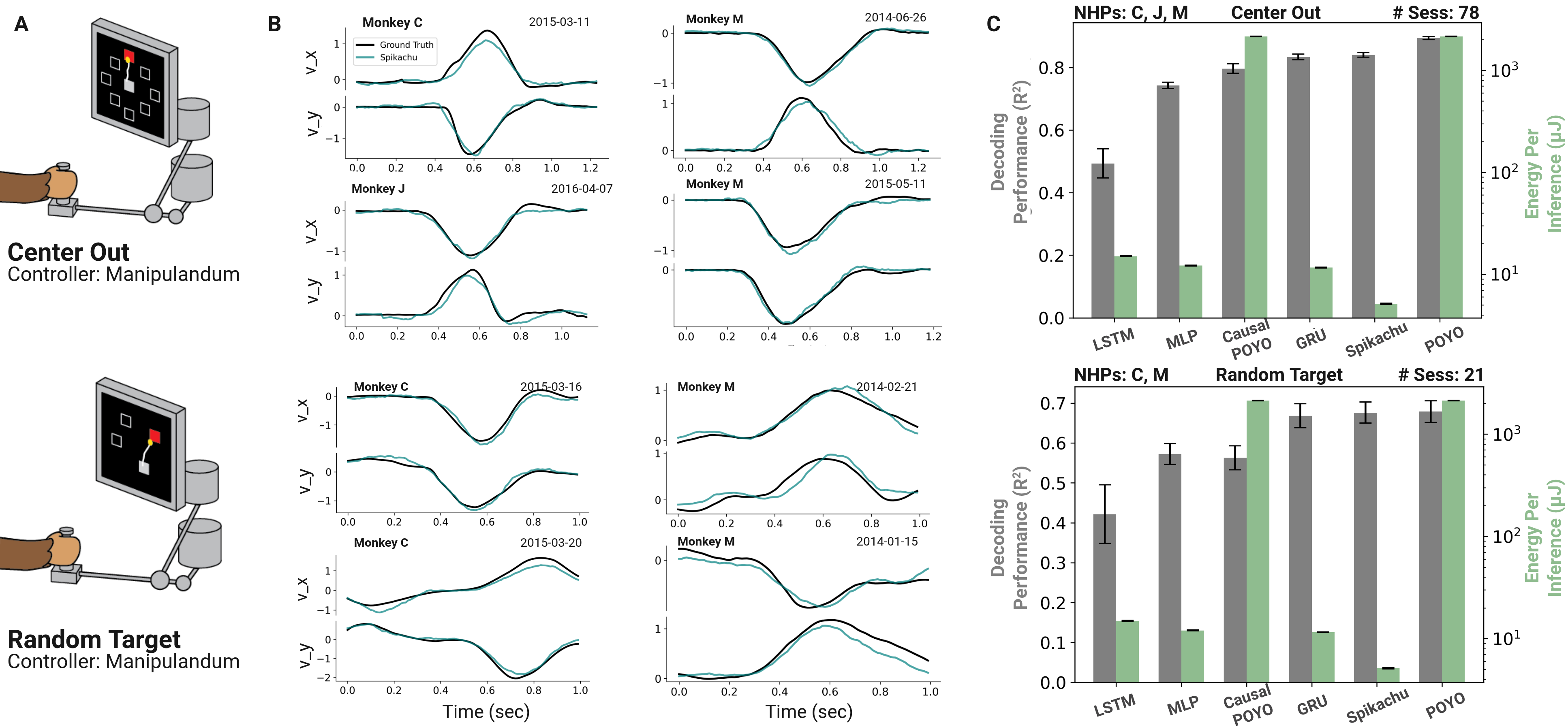
Figure 5: Benchmarking on single sessions. (A) Tasks used, (B) Examples decoded velocities, (C) Mean decoding performance and energy consumption for Spikachu and baselines.
We evaluated the models over two key axes (see Fig. 5):
- Decoding Performance: Spikachu outperformed all causal baselines while narrowing the gap with non-causal models (POYO).
- Energy efficiency: Spikachu was the most energy-efficient model across the board.
| Model | Decoding Performance (R²) ⇧ | Energy (μJ) ⇩ | ||
|---|---|---|---|---|
| Center Out | Random Target | Center Out | Random Target | |
| LSTM | 0.4935 | 0.4214 | 15.08 | 14.94 |
| MLP | 0.7424 | 0.5724 | 12.18 | 12.06 |
| POYO-causal | 0.7961 | 0.5629 | 2151.65 | 2136.82 |
| GRU | 0.8336 | 0.6681 | 11.65 | 11.54 |
| POYO | 0.8937 | 0.6785 | 2151.65 | 2136.82 |
| Spikachu | 0.8398 | 0.6761 | 5.14 | 5.13 |
Table 3: Model performance for Spikachu and baselines. Best performing model is in bold and second best model is underlined.
These results highlight Spikachu's dual promise: high-performance and energy efficiency, making it a strong candidate for power-constrained applications such as implantable BCIs.
Spikachu-mp: Building a multi-session, multi-subject model
To investigate Spikachu's ability to scale to multi-session, multi-subject data, we developed Spikachu-mp. This model was trained on the combined data of 99 recording sessions from monkeys C, J, and M from Perich et al. (2018).
To evaluate the utility of these learned representations, we finetuned Spikachu-mp on individual sessions.

Figure 6: Head-to-head comparison between Spikachu-mp + finetuning vs Spikachu trained on single-sessions. (A) Decoding Performance, (B) Energy consumption per inference.
We observed that the finetuned models outperformed models trained from scratch for nearly every session in terms of decoding performance while also consuming less energy per inference (see Fig. 6).
Transferring to new subjects
We asked whether the representations learned by Spikachu-mp could be transferred to entirely new subjects. To test this, we used data from a held-out monkey (T) who performed six sessions of the Center Out task and six sessions of the Random Target task. We compared two approaches:
- Training models from scratch on each of Monkey T’s sessions.
- Transferring from Spikachu-mp, which had been trained on monkeys C, J, and M but had never seen Monkey T’s data.

Figure 7: Tranferring Spikachu-mp to new subjects. (A). Decoding Performance, (B) Energy consumption, (C, D) Learning dynamics for the CO and RT tasks.
Head-to-head comparisons between the from-scratch and transferred models confirmed that transferred models (see Fig. 7):
- Outperformed from-scratch models in decoding accuracy.
- Required less energy per inference across all sessions.
- Learned faster than models trained from scratch.
Scaling Analysis
We were interested in profiling how Spikachu's performance scales as the amount of pretraining data increases. To investigate this, in addition to Spikachu-mp, we trained models on 20, 49, and 75 sessions from Perich et al. (2018). We then finetuned each pretrained model to three different conditions:
- Seen sessions: Finetuning on the same sessions used for pretraining.
- New sessions: Transferring to unseen sessions from the same subjects used for pretraining.
- New subject: Transferring to sessions from a completely new subject (monkey T) never seen during pretraining.

Figure 8: Scaling Analysis. (A, B) Decoding performance of finetuned/transferred models as a function of the number of pretraining sessions. Panels (C, D) Energy consumption per inference for finetuned/transferred models as a function of the number of pretraining sessions. Performance of scratch-trained single-session models overlayed in gray.
The results showed that pretrained models, after finetuning, consistently outperform models trained from scratch across all conditions. Importantly, the performance gains scaled positively with the number of sessions used for pretraining (as seen by the growing gap between colored and gray bars in Fig. 8). Together, these findings demonstrate Spikachu’s ability to scale across multi-session, multi-subject datasets, showing not just improved accuracy, but also enhanced energy efficiency.
Transferring to new animals + tasks
To further probe Spikachu's ability to generalize, we investigated whether Spikachu-mp could be transferred to entirely new conditions: a new animal performing a novel behavioral task with different recording equipment. Specifically, we used data from two held-out monkeys, L and I, from Pei et al. (2021), who performed two new tasks not included in Spikachu-mp’s pretraining. We compared two conditions:
- Training single-session models from scratch.
- Transferring from the pretrained Spikachu-mp model.

Figure 9: Generalizing to new animals + tasks. Plots show the learning dynamics for the RTT (top) and Maze (bottom) tasks.
Head-to-head comparisons between the from-scratch and transferred models showed that transferred models (see Fig. 9):
- Performed inferiorly to from-scratch models in terms of decoding accuracy.
- Required less energy per inference.
- Learned faster than models trained from scratch.
These results highlight a key tradeoff: while performance may slightly decrease in completely novel conditions, transfer learning still provided substantial gains in energy efficiency and training speed, which are critical for rapid deployment and adaptation in practical BCIs.
Conclusions
In this work, we introduced Spikachu: a causal, scalable, and energy-efficient framework for neural decoding based on spiking neural networks. Contrary to other frameworks, Spikachu offers a balanced performance in terms of energy efficiency, causality, scalability, and generalization.
| Model | Energy efficiency | Causality | Scalability | Generalization |
|---|---|---|---|---|
| "Simple": Wiener Filter, MLPs, GRUs, ... | ➖ | ✚ | ➖ | ➖ |
| "Sophisticated": Cebra, LFADS, POYO, MICrONS, ... | ➖ | ➖ | ✚ | ✚ |
| Spikachu | ✚ | ✚ | ✚ | ✚ |
Table 4: The landscape of neural decoders + Spikachu
By uniting energy efficiency, causality, scalability, and generalization, Spikachu paves the way for practical, reliable BCIs that can make a real impact in clinical and assistive settings.
Acknowledgements
This website was built using code from https://poyo-brain.github.io and https://gmentz.github.io/seegnificant.
Citation
If you find this useful for your research, please consider citing our work: @misc{mentzelopoulos2025spikachu,
doi = {10.48550/ARXIV.2510.20683},
url = {https://arxiv.org/abs/2510.20683},
author = {Mentzelopoulos, Georgios and Asmanis, Ioannis and Kording, Konrad P. and Dyer, Eva L. and Daniilidis, Kostas and Vitale, Flavia},
keywords = {Machine Learning (cs.LG), Artificial Intelligence (cs.AI), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {A Scalable, Causal, and Energy Efficient Framework for Neural Decoding with Spiking Neural Networks},
publisher = {arXiv},
year = {2025},
}